Mutual Learning in Neural nets and Hint-based pretraining for improved accuracies
Knowledge Distillation framework is a cool, easy to understand and yet effective tranfer-learning technique which has also been used as a model-compression strategy. In this blog, we will talk about a variant of knowledge distillation called ‘Mutual Learning’ and run an experiment adopting an idea to enhance this technique to give rise to better generalisation capabilities.
One of things cool about the Deeplearning community is their effort to relate the ideas in the field to simple daily phenomena which many can correlate with*. We all know how Geoff Hinton teaches about neural architectures connecting them with the workings of the brain. In similar fashion in 2014, Hinton et. al[1] proposed a neural compression framework called ‘Knowledge Distillation’. The idea is very simple: the typical way to get an easy boost of 2% accuracy is to use an ensemble and average out your predictions**. As can be seen this setup is computationally expensive when it is used to serve a lot of users. In a classification problem, if each model is in a different minima and is good at classifying particular classes, KD framework proposes*** a technique to combine/distill this individual classification specialities into one neural net which has usually less number of parameters than any of the models in the ensemble.
KD:
Let’s consider just a binary case of having one well-trained good classifier referred as ‘Teacher’ and another small(in terms of parameters, not depth) network which is to distill classifaction abilties from the teacher referred as a ‘Student’. How would a normal neural model learn typically: iterating over a ton of traininig data using a CrossEntropy loss function. KD framework proposes an additional transfer learning objective to this loss fn which helps to distill knowledge from the teacher network. The idea in KD framework is to force the student networks output distribution to be as close as to the teacher’s output distribution while it is parallely learning on it’s own from the training set using a CE loss.
(Written in terms of a for loop just for simplicity. It should be batched in implementations)
For a batch of ‘n’ examples classified over ‘m’ classes, the Student loss would be:
For all i to batch_n:
$\qquad$ StudentLoss(i) $+=$ CEloss(i) $+$ KLloss(i)
where KLloss is the KLdivergence between between teacher’s output distribution, $p_t$ and the student’s output distribution, $p_s$:
QuickNote: Loss functions donot use a size average formulation for effective gradient flow in deep networks.
This technique worked well in many instances although it depends partly on a suitable student network architecture. The student network needed just a smaller number of training examples to learn as it is reliant on stronger, smoother classifier. One such instance where is transfer learning technique is used is [3] where knowledge from a strong coloured image classifier(Image net) is used to train a Depth classifier net overcoming the dearth in depth images training set problem. (Isn’t the technique simple using analogies like Teacher’s and Student’s)
Mutual learning:
Mutual learning[4] extends the teacher-student model with a small modification and claims to achieve better performances. Instead a single student learning from one static strong teacher model, in mutual learning there will be a cohort of students all trying to learn from eachother. (The paper makes the analogy of a group study night :) ) . Their algorithm in words is: If we consider a cohort of K students, for every batch of examples, each of the student model is enforced with ’k’ gradient updates: One update for each student trying to learn from the posteriors of the rest ’k-1’ student networks. Constraining ourselves to a two cohort network, we will have two gradient updates. The training algorithm for this two-cohort network is as follows:

The algorithm states that its effectiveness and working is largely because of the random initialisation of the weights in student networks when the training starts. While each student is intialized to their own setting placing them in different optimization points , they are driven by the CELoss to move towards the hard label target distribution. While doing this, transferring each other posterior information leads to a better higher entropy state with a better minima such that it lies in a wide valley of the landscape rather than a narrow one. Look at the paper’s discussion section for more information on this point.
Taking their explanation at word, I thought to perform an experiment by pretraining each student net by intializing each of the student nets to an expectedly different optimization points using a Fitnet [2] based approach. In the fitnet based approach, the student’s middle layer is forced to match the scores of the parent’s middle layer using a L2 loss. Approaches like these have been used as pre-training for Deep networks to ease the training of deep networks and lead to faster convergence. Indeed, the fitnets pre-training approach claims to reach faster convergences when deep student nets. I have just applied the same idea by pre-training each of the students in the cohort with middle-layers scores from the teacher network and expectedly placing them in different optimization landscapes and then on doing mutual-training the student models might reach broader minimums leading to better generalisations. A quick experiment shows that this idea helped the student nets trained by mutual-learning approach reach better generalisation abilities. (However, more investigation will ofcourse be needed to validate this claim)
Quick Experiment:
In this experimental setup, we will one teacher network which has more number of parameters and two student networks which have relatively less parameters, but more depth. The models were trained on CIFAR-10 dataset.
Individual Training:
The bulkier teacher is a VGG inspired network but minimal than it. It’s architecture can be described as: (32, ’M’, 64, ’M’, 128, 128, ’G’, ’M’, 256, 256, ’M’, 256, 256, ’M’) where each number at index ‘i’ says the number of activation units at layer ‘i’, ‘M’ represents 2*2 Maxpool operation just as in VGG, ‘G’ is the guided layers whose scores will be targeted by the student networks.
The teacher has 2440394 parameters. This network is trained till convergence(30 epochs) to reach a 74% validation accuracy
We then model a thinner but deeper student network which has 1497434 parameters of architecture: (16, 16, ’M’, 32, 32, ’M’, 64, 64, 64, ’H’, ’M’, 128, 128, 128, ’M’, 256, 256, ’M’), where ’H’ represents the hint layer. When trained individually the student network converges to 67% accuracy.
Both the networks were trained using Adam optimiser with it’s common default initial settings(lr = 1e-3)
We could see the teacher network able to train well(74%) and generalise better owing to it’s large bulkier model when compared to the student model(67%)
Mutual Learning setup:
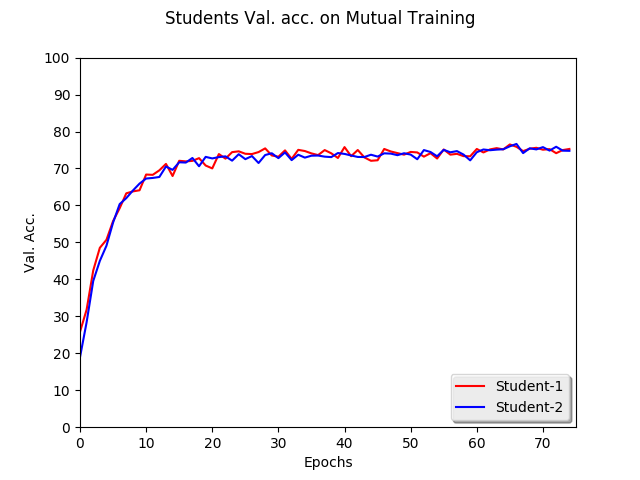
Now let’s use the same student architecture but train using the mentioned Mutual learning technique. Both students increase their generalisation
capabilities to 74.17% and 73% validation accuracies. As a worthy note, the optimiser initial settings were different here than when trained individually: I have used an initial lr of 3e-4 and betas(0.5, 0.99)
The below plot shows the accuracy trend for both the students:
Hint-based pretrained Mutual Learning setup:
We then use our enhanced mutual learning approach by using hint-based weight initialization of all weights till the hint layer for both students. The pretraining is done for 10 epochs with Adam(1e-3) learning setting. After this pre-training we proceed to use the mutual learning framework to train the students. We could see that the student models have converged with validation accuracies of 76.7 and 77.03 which is way greater than the traditional mutual learning approach.
Also note the relative faster spike in accuracies at the start owing to the pre-training done.
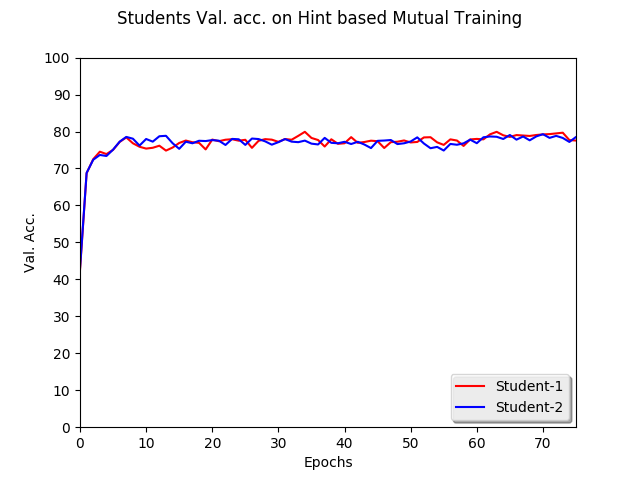
The students were able to reach better generalisation accuracies even with a reduction 63% in parameter size.
The above experiment can help understand empirically that deep student networks are difficult to transfer-train, and overcoming this problem by hint-based pre-training we can enhance the mutual-learning technique to produce better accuracies.
* - These could be bad if done too much stretching the analogy, but it helps many to correlate and start with
** - Check the leaderboard of SQUAD for instance and note the differences between the ensemble version and the plain one
*** - Inspired by Caruana’s earlier work
REFERENCS:
[1] Knowledge Distillation in NeuralNets: https://arxiv.org/abs/1503.02531
[2] Fitnets : https://arxiv.org/abs/1412.6550
[3] CrossModal distillation: https://www.cv-foundation.org/openaccess/content_cvpr_2016/papers/Gupta_Cross_Modal_Distillation_CVPR_2016_paper.pdf
[4] MutualLearning: https://arxiv.org/abs/1706.00384